
How To Evaluate AI Recruiting Tools (Scorecard Template)
Learn how to evaluate AI recruiting tools using a scorecard that prioritizes automation, compliance, and outcomes.
.png)
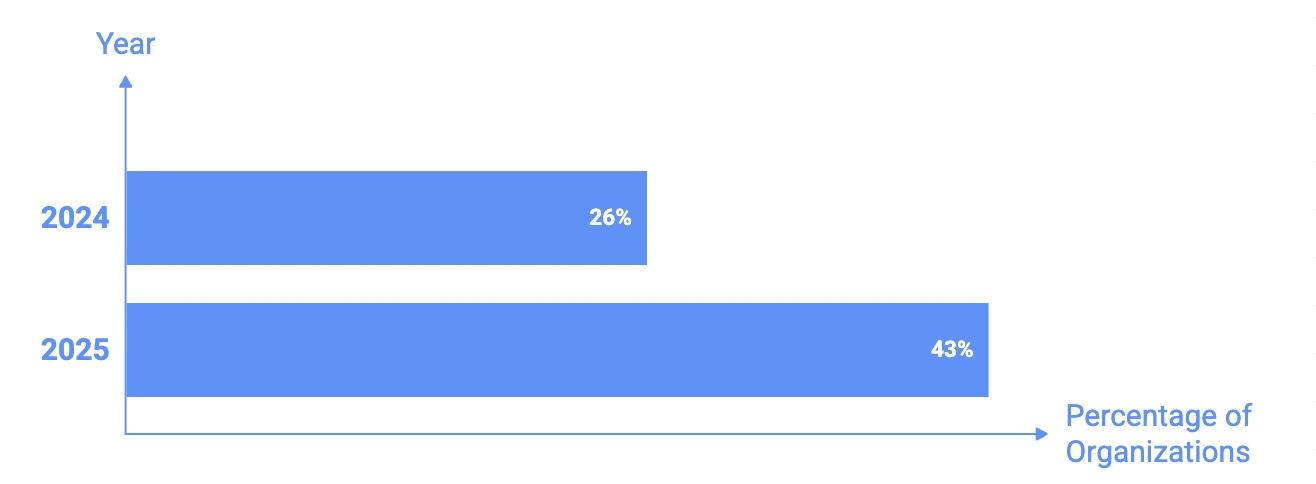
AI recruiting tools are everywhere, and adoption is accelerating fast. In 2025, 43% of organizations reported using AI for HR and recruiting, up sharply from 26% just a year earlier. At the same time, vendors promise everything from automated sourcing to instant hiring decisions, all powered by AI. On the surface, the category looks mature, sophisticated, and full of progress, but many teams learn the hard way that great demos don’t equal great outcomes.
Industry research consistently shows that most AI initiatives struggle to move beyond pilots or fail to deliver meaningful impact in production. In recruiting, the pattern is familiar: workflows stall, edge cases pile up, compliance gaps surface late, and recruiters end up doing the same manual work just spread across more tools.
The core problem here is the lack of rigorous evaluation.
Most teams don’t have a clear framework to assess whether a tool will actually remove work, hold up at scale, and perform under real-world hiring conditions, where data is messy, volume spikes erratically, and mistakes are costly.
This guide walks through a practical, step-by-step method to evaluate AI recruiting tools, focusing on what matters in production over sounds good in sales meetings. We’ll break down the core dimensions to assess, the questions to ask vendors, and the common traps that cause otherwise promising tools to fail.
At the end, we’ve included a simple scorecard template you can use to compare tools, side by side. and make a decision grounded in outcomes, not promises.
Continue reading: Best AI Recruiting Tools 2026
Why Most AI Recruiting Tool Evaluations Go Wrong
AI tool adoption has jumped sharply year over year, but outcomes haven’t kept pace. The reason is simple: most evaluations optimize for what looks good in demos and pilots, not what survives in production.
Here’s where teams consistently go wrong.
1. Buyers Rely on Feature Lists, Not Outcomes
A common trap is evaluating tools based on what they claim to do (features) instead of what they actually deliver (outcomes). Recruiters still spend a disproportionate amount of time on manual tasks such as screening and coordination, even with automation tools in place.
Research suggests recruiters spend about 60% of their time on administrative tasks that modern systems could handle, yet teams often buy tools that only recommend actions rather than execute them.
Tools that look good in demos fail to reduce cycle times in real hiring workflows.
2. Pilots Don’t Reflect Real Hiring Conditions
According to broader research on AI adoption, 80% of AI initiatives fail, and only about 30% progress beyond the pilot stage, often when integration with real workflows is missing or incomplete.
This pattern holds in recruiting: a successful pilot that screens resumes in a controlled setting often breaks down when exposed to messy, real-world candidates, missing data, or compliance requirements that vary by geography or role.
3. AI Bias and Lack of Transparency Undermine Trust
AI systems can amplify bias or produce opaque decisions when trained on biased or incomplete historical data. Algorithmic bias can lead to unfair outcomes skewed toward certain demographic groups, which, in recruiting, can translate to unequal opportunities for candidates.
This problem often isn’t discovered until late in the evaluation process because vendors showcase accuracy on sanitized datasets, not behavior under real-world conditions.
4. Misplaced Confidence in Novel Tech
While AI adoption in recruiting is rising quickly, many teams are not prepared to analyze or govern these systems. In one report on hiring technologies, only 37% of recruiting leaders felt well prepared to handle shifts in AI and automation, even as most planned to invest in new tech.
Under-prepared teams tend to assume that any AI is better than none, rather than scrutinizing how that AI performs across edge cases, compliance scenarios, or during peak volumes.
What You Should Evaluate Instead: The 5 Core Dimensions
Evaluating AI recruiting tools through feature checklists and marketing claims leaves teams vulnerable to products that look capable but don’t deliver in production. Instead, every tool should be assessed across five core dimensions that directly influence operational impact, risk exposure, and real-world throughput.
These dimensions are:

Unlike feature lists or model complexity claims, these dimensions are tied to actual outcomes that matter to HR operations, recruiting velocity, compliance leadership, and executive sponsors.
In the sections that follow, we’ll unpack each dimension, explain why it matters in real usage, and provide clear scoring guidance you can use in your evaluations.
Dimension 1: Automation Depth (Does It Actually Remove Work?)
Does this tool execute recruiting work end-to-end or merely suggest actions that humans still have to complete?
Many AI recruiting tools position themselves as automation, but in practice, they function as decision-support layers. They surface insights, recommendations, or flags, while recruiters still handle execution: chasing candidates, re-uploading documents, toggling portals, or resolving errors.
What to look for:
- Can the system run workflows without human intervention?
- Does it trigger actions automatically when conditions are met?
- Are exceptions handled automatically, or routed into queues?
- Does automation stop at recommendation, or extend to execution?
Recruiting bottlenecks don’t come from lack of insight; they come from manual handoffs. Tools that don’t remove steps won’t reduce cycle time, even if they claim to be AI-powered.
Scoring guidance (1-5)
- 1: AI suggestions only; humans execute everything
- 3: Partial automation with frequent manual intervention
- 5: End-to-end automation with exception handling
Dimension 2: Accuracy in Real-World Conditions
How does the system behave when data is messy, incomplete, or incorrect (a common occurrence in recruiting)?
Most vendors demonstrate accuracy using clean, historical datasets. In production, inputs look very different: blurry documents, name mismatches, missing fields, expired credentials, or inconsistent records across systems are common.
What to look for:
- How does the tool handle invalid or incomplete inputs?
- Are errors detected at the point of submission or discovered later?
- Does the system explain why something failed?
- Can issues be resolved without ops intervention?
Late-stage error detection creates rework, candidate drop-offs, and compliance risk. Early, explainable validation improves throughput consistently.
Scoring guidance (1-5)
- 1: Breaks or stalls on imperfect inputs
- 3: Flags issues but requires ops cleanup
- 5: Detects, explains, and routes fixes automatically
Dimension 3: Compliance, Auditability, and Risk
Can every decision and action taken by the system be explained, traced, and proven during an audit?
As AI becomes more embedded in hiring decisions, regulatory scrutiny is increasing. Tools that can’t provide audit trails, evidence, or clear decision logic expose teams to risk, even if outcomes look good initially.
What to look for:
- Immutable audit logs for every action
- Evidence capture (records, screenshots, timestamps)
- Clear separation between AI decisions and human overrides
- Built-in bias controls and review mechanism.
Compliance failures don’t surface during demos; they surface during audits, lawsuits, or peak hiring seasons. Auditability must be designed in, not bolted on.
Scoring guidance (1-5)
- 1: No audit trail or explainability
- 3: Partial logs, manual evidence collection
- 5: Default audit readiness with full traceability
Dimension 4: Time to Value (Implementation Reality)
How quickly does the tool deliver measurable impact in production?
Long implementations are often justified as enterprise-grade, but extended timelines delay ROI and increase the risk of abandonment. Many AI recruiting tools never move beyond pilot because they require clean data, deep integrations, or heavy customization before value appears.
What to look for:
- Time from contract to live workflows
- Dependency on data preprocessing or system overhauls
- Ability to work with legacy or non-API systems
- Evidence of production impact within weeks
Speed to value determines whether a tool becomes infrastructure or shelfware.
Scoring guidance (1-5)
- 1: More than 3 months to first impact
- 3: Limited pilot success
- 5: Measurable production impact in weeks
Dimension 5: Candidate and Operator Experience
Does the tool reduce friction or simply shift it from recruiters to candidates or ops teams?
Many systems optimize recruiter dashboards while degrading the candidate experience: delayed feedback, unclear error messages, repeated resubmissions, or stalled workflows. That friction shows up as drop-offs and lost starts.
What to look for:
- Real-time feedback to candidates
- Clear guidance when issues occur
- Reduced resubmissions and rework
- Lower recruiter involvement during peak volume
Poor experience isn’t just a UX problem; it directly impacts fill rates, time-to-start, and revenue.
Scoring guidance (1-5)
- 1: Adds steps or confusion
- 3: Neutral impact
- 5: Actively reduces drop-offs and manual follow-ups
How to Use These Dimensions
Each dimension maps directly to operational outcomes: speed, risk, and scale. In the next section, we’ll combine them into a weighted scorecard you can use to compare vendors side by side so decisions are grounded in results, not promises.
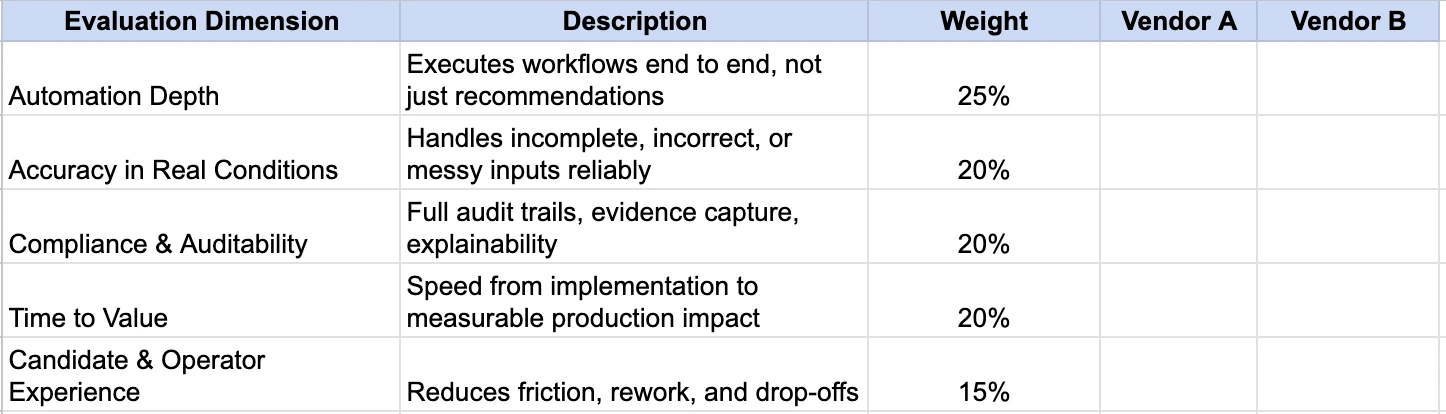
The AI Recruiting Tool Evaluation Scorecard
Once you’ve assessed vendors across the five core dimensions, the next step is to compare them objectively. The goal of a scorecard isn’t to “pick the smartest AI.” It’s to identify the tool that will reduce cycle time, lower risk, and scale under real hiring conditions.
This scorecard uses weighted scoring to reflect what actually matters in production.
How the Scorecard Works
- Score each dimension from 1 (poor) to 5 (excellent) based on what you see in demos, pilots, and reference calls.
- Apply the suggested weight to each dimension.
- Add up the weighted scores to get a total of 100.
- Compare vendors on total score, not individual features.
Common Evaluation Mistakes to Avoid
Most failed AI recruiting deployments fail because teams evaluate the tools in ways that hide risk until it’s too late. These are the mistakes that recur and how to avoid them.
1. Optimizing for Features Instead of Throughput
Teams often choose tools with the longest feature lists or the most impressive AI terminology. In practice, those features don’t matter if they don’t reduce cycle time.
A tool can support sourcing, screening, and compliance while still requiring recruiters to perform the same manual work across more screens. Evaluate whether each feature removes a step, not whether it exists.
2. Trusting Pilot Success as Proof of Scale
Pilots are controlled environments. Volume hiring is not. Many tools perform well with small candidate sets, clean data and dedicated ops support
They fail when exposed to peak hiring volume, edge cases and inconsistencies in real-world data. Pilots hide the cost of human intervention. Score vendors based on observed behavior under stress, not pilot outcomes alone.
3. Ignoring Compliance Until Legal Raises a Flag
Compliance is often treated as a downstream concern, something to “check later.” By the time issues surface audit trails are incomplete, evidence is missing and decisions can’t be explained retroactively.
Compliance cannot be retrofitted without re-architecting workflows. Require vendors to demonstrate audit readiness by default, not as an add-on.
4. Overvaluing Intelligence, Undervaluing Execution
Teams are drawn to advanced models, accuracy percentages, and discussions of AI architectures. Intelligence without execution creates insight, not outcomes. Weight automation depth is higher than model sophistication in evaluations.
5. Treating Candidate Experience as Secondary
Candidate friction is often framed as a “UX issue.” In reality, it directly affects hiring throughput. Poor feedback loops, unclear errors, and repeated resubmissions lead to:
- Higher drop-offs (60% higher drop offs as seen on Firstwork)
- Delayed starts
- Lost revenue
Every extra step compounds at scale. Evaluate tools on how they behave when candidates make mistakes, not when everything goes right.
6. Assuming Integration Equals Readiness
Deep integrations are often mistaken for operational maturity. In reality, some of the most critical recruiting workflows live in legacy systems, government portals and client-specific tools without APIs.
Tools that depend entirely on clean integrations stall when reality intervenes. Assess whether the system can operate with or without APIs.
Final Advice: Evaluate for Throughput, Not Intelligence
When evaluating AI recruiting tools, the goal isn’t to predict the future of AI. It’s to choose infrastructure that holds up when volume spikes, data is messy, and mistakes are expensive. Tools that optimize for demos, dashboards, or novelty rarely survive that test.
If you’re hiring at volume and want to see what real automation, audit-ready compliance, and faster time-to-start look like in practice, we’re happy to walk you through it.
Book a demo with Firstwork to see how teams eliminate manual recruiting work and move candidates into productive roles faster without increasing risk.